Building an Internal Developer Platform on EKS
Building an Internal Developer Platform on EKS
An internal developer platform is not just a cluster plus CI/CD. This guide shows how Backstage, GitOps, and EKS fit together as a product layer for self-service delivery.
TL;DR
An internal developer platform on EKS works best when you treat it as a product, not a cluster project. EKS provides the runtime substrate, but the platform is the contract layer that turns infrastructure into self-service capabilities: catalog, templates, deployment paths, health visibility, and guardrails. Backstage is useful because its catalog and software templates expose those capabilities in a developer-facing interface, while GitOps keeps the actual platform state declarative and auditable. If you want adoption, focus on what developers can request and understand, not only on what the cluster can run.
An IDP Is A Product Layer, Not A Cluster Project
The easiest way to build the wrong internal developer platform is to treat it like an infrastructure checklist. If the project only delivers EKS, a CI pipeline, and a few shared Helm charts, developers still end up asking for help in Slack, waiting on manual approvals, and guessing which template, namespace, or owner they are supposed to use.
An internal developer platform is the contract layer that sits on top of the runtime. EKS is part of the foundation, but the platform is the product that turns infrastructure into self-service capabilities: catalog, templates, deployment paths, health visibility, and guardrails.
That contract usually includes:
- A software catalog so teams can find owned services and the people responsible for them.
- Templates so new services start from a controlled baseline instead of copy-paste drift.
- GitOps so the platform state stays declarative, reviewable, and auditable.
- Deployment and health visibility so service owners can understand what happened without cluster-admin access.
- Guardrails so teams can move quickly without bypassing policy.
The Operating Model
The right mental model is to keep five layers separate:
- Portal: the user interface developers interact with.
- Catalog: the inventory of software entities, owners, and relations.
- Templates: the approved way to create new services or platform assets.
- GitOps: the reconciliation loop that keeps declared state in sync.
- Runtime: the actual cluster, workloads, and cloud resources.
If you blur those layers together, the platform becomes impossible to reason about. The portal is not the platform. The catalog is not the runtime. CI/CD is not enough by itself. A useful IDP makes those boundaries explicit.
Backstage Gives You The Product Surface
Backstage fits this model because it treats software as first-class entities and layers templates and plugins around those entities. The Backstage catalog is a centralized system for ownership and metadata. The catalog lives on top of metadata YAML files stored in Git, not in a hidden database that only the portal can understand.
The critical part is not just visibility. It is ownership.
Backstage describes a Component as a unit of software with a distinct deployable or linkable artifact. For that kind, spec.type, spec.lifecycle, and spec.owner are required. The docs are also explicit that ownership is about the singular entity, commonly a team, that bears ultimate responsibility for the component.
That entity model is what makes the platform legible. Component is the thing you deploy. System is the logical product area that groups related components. Domain is the broader business boundary. Resource covers supporting infrastructure such as databases, queues, or clusters. The point is to capture the real structure of the organization in a machine-readable graph, not just list services in a portal.
apiVersion: backstage.io/v1alpha1
kind: Component
metadata:
name: checkout-service
description: Checkout service for the commerce platform
spec:
type: service
lifecycle: production
owner: team-commerce
system: ecommerce-platform
dependsOn:
- resource:default/eks-prod-clusterThat descriptor is more than a formality. It is the contract developers use to answer basic questions:
- What is this service?
- Who owns it?
- Is it experimental, production, or deprecated?
- What system does it belong to?
- What does it depend on?
Backstage relations are also important. The descriptor docs explain that processors can deduce relations and attach them to the entity, and that plugins should consume the relation rather than relying only on spec.owner. That matters because ownership can also come from neighboring signals, such as CODEOWNERS or processor logic.
In practice, the platform team usually wants a small set of canonical descriptors and locations, not dozens of hand-maintained copies. A catalog location can point Backstage at the repositories or folders that contain entity YAML, and then the processors can validate, enrich, and stitch those entities into a usable graph.
apiVersion: backstage.io/v1alpha1
kind: Location
metadata:
name: platform-catalog
spec:
targets:
- https://github.com/acme/commerce-platform/blob/main/catalog-info.yaml
- https://github.com/acme/payments-service/blob/main/catalog-info.yamlThat is what makes ownership belong in Git-backed descriptors. The source of truth is reviewable, diffable, and portable. If the team changes ownership, lifecycle, or system boundaries, the change goes through code review instead of a portal-only edit that nobody else can audit.
The Catalog Is A Lifecycle, Not A YAML File
One of the most common mistakes is to assume that putting a catalog-info.yaml file in a repo solves the catalog problem. It does not.
The Backstage catalog lifecycle has three distinct stages:
- Ingestion, where providers fetch raw entity data from external sources.
- Processing, where policies and processors validate and enrich the data.
- Stitching, where the outputs are assembled into the final entity Backstage shows.
That lifecycle is what makes the catalog useful at scale. The most common source is still YAML files near the code they describe, but the docs are clear that Backstage can ingest authoritative entities from multiple places and keep them up to date.
Discovery is where teams find the entity in the first place, usually through a Location or a catalog provider. Registration is the act of adding it to the catalog graph. Processing is where Backstage can check schema, infer relations, and attach useful metadata. Stitching is the last step: it combines the raw inputs into the entity that the portal, plugins, and search experience actually consume.
apiVersion: backstage.io/v1alpha1
kind: Component
metadata:
name: payments-api
description: Payments API owned by the platform commerce team
tags:
- golang
- payments
- eks
spec:
type: service
lifecycle: production
owner: team-commerce
system: checkout-platform
providesApis:
- payments-apiThe practical implication is simple. If another system is authoritative for part of the graph, let Backstage ingest that data instead of forcing people to duplicate it by hand. Otherwise the catalog drifts into a stale copy of reality.
Templates Turn Opinion Into Self-Service
Backstage software templates are where the platform team encodes the approved path. The templates live under /create, and the docs encourage a real UX rather than a raw YAML form. The most useful field here is OwnerPicker, because it lets users choose from existing users and groups already in the catalog.
apiVersion: scaffolder.backstage.io/v1beta3
kind: Template
metadata:
name: service-backend-template
title: Standard service scaffold
description: Create a GitOps-ready service with catalog metadata, repo scaffolding, and ownership controls.
spec:
owner: team-platform
type: service
presentation:
buttonLabels:
backButtonText: Return
reviewButtonText: Verify
createButtonText: Create Service
parameters:
- title: Service metadata
required:
- owner
- repoUrl
- name
properties:
name:
type: string
title: Service name
description: Unique, DNS-safe name for the component.
owner:
title: Owner
type: string
ui:field: OwnerPicker
ui:options:
catalogFilter:
kind: [Group]
system:
type: string
title: System
description: Logical product area the service belongs to.
repoUrl:
title: Repository location
type: string
ui:field: RepoUrlPicker
ui:options:
allowedHosts:
- github.com
allowedOwners:
- platform-engineering
requestUserCredentials:
secretsKey: USER_OAUTH_TOKEN
steps:
- id: fetchTemplate
name: Fetch skeleton
action: fetch:template
input:
url: ./skeleton
- id: publish
name: Publish to Git
action: publish:github
input:
repoUrl: ${{ parameters.repoUrl }}
token: ${{ secrets.USER_OAUTH_TOKEN }}
- id: register
name: Register in catalog
action: catalog:register
input:
repoContentsUrl: ${{ steps.publish.output.repoContentsUrl }}That is the difference between a portal and a platform product. The platform team controls the shape of the request, the required fields, and the approved ownership model. Application teams still get self-service, but they do not get to invent the platform contract every time they create a service.
The template should also encode the things that are hard to remember and easy to get wrong: repository visibility, branch naming conventions, catalog registration, and any starter configuration required for GitOps or documentation. Backstage’s template docs explicitly support a RepoUrlPicker and owner pickers for exactly this reason: the scaffold should guide the user toward valid choices, not accept arbitrary input and hope the platform catches up later.
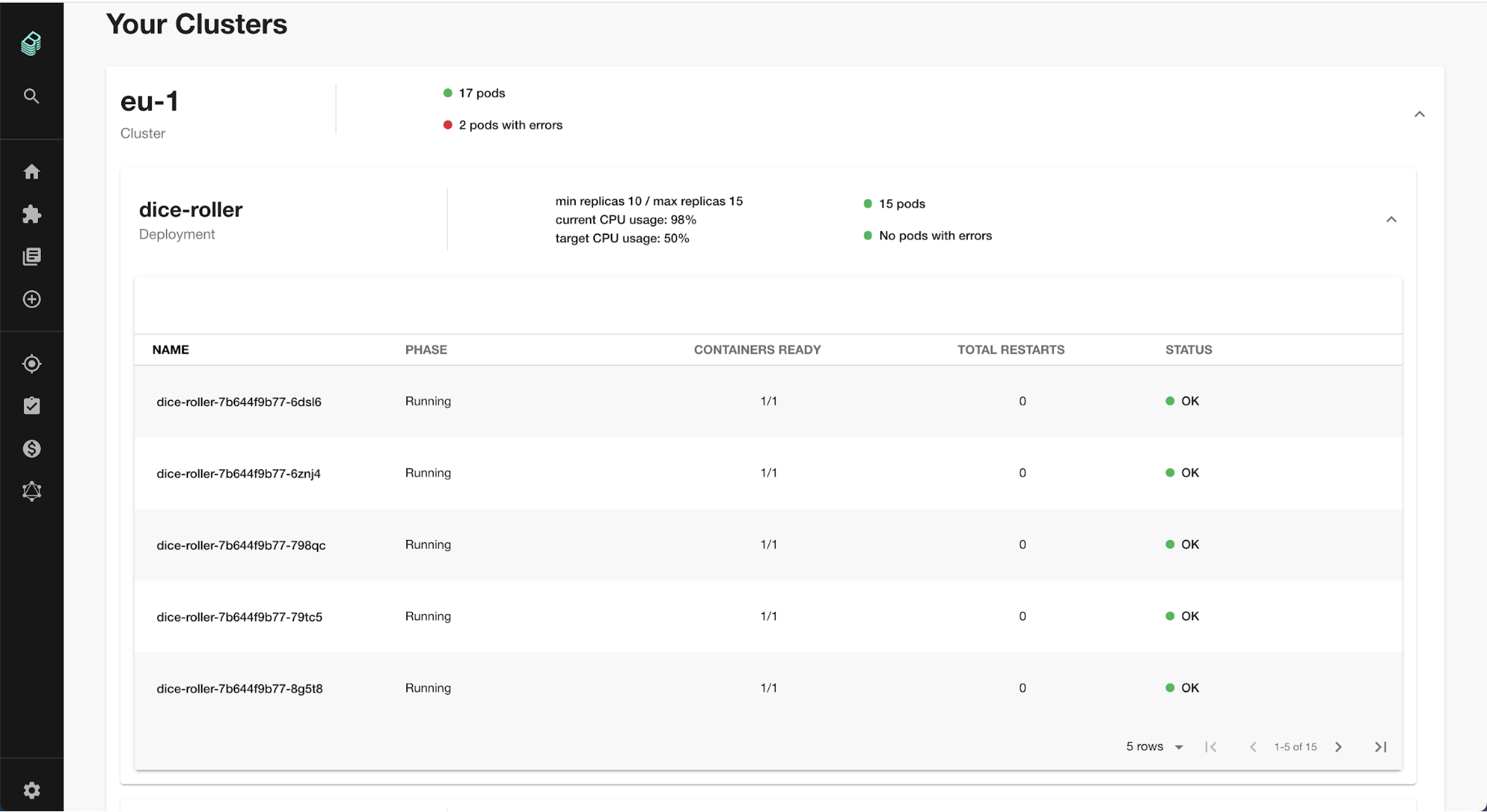
How The Runtime View Gets Stitched Back
The catalog is most useful when it is linked to runtime signals. That is where the Backstage Kubernetes plugin fits. It is not a cluster-admin console; it is a service-owner view of workloads, deployments, and health that can be stitched to the catalog entity.
The practical result is that a developer can start at a service entry, follow it to the owned workloads, and inspect whether the cluster agrees with the desired state. That is more useful than exposing raw cluster objects with no ownership context.
EKS Is The Runtime Layer
Amazon EKS is the right foundation when you need managed Kubernetes, AWS integration, and a standardized place to run workloads. But EKS alone is not an internal developer platform.
The platform still needs:
- A catalog that explains what is running.
- A templating path that creates new services consistently.
- A deployment path that stays auditable.
- A set of guardrails that protect the cluster without slowing every team down.
That is why the IDP discussion should not start with "Which cluster flavor do we want?" It should start with "What do developers need to request, understand, and operate without platform intervention?"
The Backstage Kubernetes plugin is useful here because it is designed around service owners, not cluster admins. The docs say the frontend plugin exposes information in a digestible way, while the backend handles connections to clusters to collect the relevant information. That gives service owners the health and drill-down they need without handing them the whole cluster.
GitOps Turns The Platform Into A Contract
OpenGitOps is useful because it gives you a simple operating model: declarative desired state, versioned and immutable history, pulled automatically, and continuously reconciled. That is a better fit for a platform than one-off imperative setup scripts.
In practice, GitOps does two jobs for an IDP:
- It keeps platform state reviewable and auditable.
- It reduces the number of ways the platform can drift from the documented contract.
The AWS EKS Argo CD guide and the EKS Blueprints GitOps bridge pattern show how platform teams can separate bootstrap from day-2 operations. Terraform and AWS provisioning establish the substrate, and Argo CD keeps the in-cluster pieces aligned with Git.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: platform-base
namespace: argocd
spec:
project: platform
source:
repoURL: https://github.com/aws-samples/eks-blueprints-add-ons
targetRevision: main
path: argocd/bootstrap/control-plane/addons
destination:
server: https://kubernetes.default.svc
namespace: argocd
syncPolicy:
automated:
prune: true
selfHeal: trueArgo CD is not the whole platform either. It is the reconciliation loop that keeps the platform definition honest. AWS documents the EKS Argo CD capability as fully managed and notes that the software runs in the AWS control plane, not on worker nodes. That matters because it lets teams adopt GitOps without turning the GitOps controller itself into another thing they must operate.
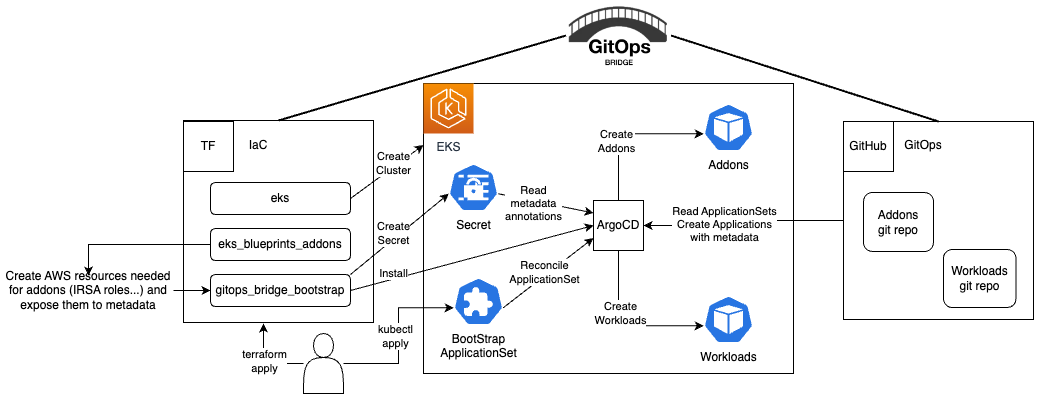
The bridge pattern is helpful when add-ons need cloud-side metadata such as VPC IDs, IAM role ARNs, cluster names, or repository paths. The AWS Blueprints guide shows Terraform writing that metadata into the Argo CD cluster secret so GitOps can pass it into the Helm chart at install time.
metadata:
annotations:
addons_repo_path: bootstrap/control-plane/addons
addons_repo_url: https://github.com/aws-samples/eks-blueprints-add-ons
addons_repo_revision: main
aws_cluster_name: getting-started-gitops
aws_region: us-west-2
aws_vpc_id: vpc-001d3f00151bbb731
workload_repo_path: getting-started-argocd/k8sThat is the real value of the pattern. Terraform owns the cloud facts. GitOps owns the installed state. The metadata bridge prevents those systems from fighting over the same concern.
Multi-Cluster Changes The Design
The EKS Argo CD concepts docs also matter because they define the topology decisions you need to make early. AWS describes two main patterns:
- Hub-and-spoke, where Argo CD runs on a dedicated management cluster and deploys to multiple workload clusters.
- Per-cluster, where each cluster manages only its own applications.
For a platform team, hub-and-spoke is usually the better default because it gives you centralized control, consistent policy, and a clear control-plane boundary. Per-cluster makes sense when teams are fully isolated or when you want to reduce cross-cluster coupling.
The important point is that the IDP should make those choices explicit. If a team needs a single cluster experience, the platform should say so. If the platform must manage several clusters, the portal and catalog should still present the same service contract to developers.
An ApplicationSet is useful here when you want one Git definition to fan out across multiple clusters or environments. The value is not magic automation; it is consistency. The same repo path, chart, or overlay can target many clusters while the catalog continues to point the developer at one logical service.
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: platform-addons
spec:
generators:
- clusters: {}
template:
metadata:
name: platform-addons-{{name}}
spec:
project: platform
source:
repoURL: https://github.com/acme/platform-gitops
targetRevision: main
path: addons/base
destination:
name: "{{name}}"
syncPolicy:
automated:
prune: true
selfHeal: trueThat is the multi-cluster lesson in practice: the developer sees one service, while the platform reconciles many cluster targets in a controlled way.
What Backstage Does Not Do
Backstage is powerful, but it is not the whole answer.
- It does not provision your Kubernetes clusters.
- It does not replace GitOps reconciliation.
- It does not make the catalog the source of truth by itself.
- It does not eliminate platform ownership.
- It does not remove the need to decide which layer owns templates, runtime defaults, and policy.
- It does not own release promotion or traffic shaping.
- It does not replace Kubernetes-native runtime health or AWS control-plane permissions.
That clarity matters because teams often over-rotate on the UI. A portal without a real platform contract becomes a nice front door on top of manual work.
Platform Team Versus App Team
This is the boundary that decides whether the IDP scales.
Platform team owns
- Cluster defaults and baseline configuration.
- Service templates and scaffolding guardrails.
- Catalog schema and metadata hygiene.
- Deployment automation and GitOps control plane.
- Observability and runtime integration.
Application team owns
- Service code and tests.
- Service metadata in the catalog.
- Runtime configuration that belongs to the service.
- Accepting or rejecting generated scaffolding.
That split is what keeps the platform useful. The platform team provides the paved road. Application teams drive on it and own what they put on the road.
A Practical AWS Shape
A credible IDP on EKS usually looks like this:
- AWS and Terraform provision the network, cluster, and shared services.
- GitOps tools reconcile the cluster add-ons and platform applications.
- Backstage exposes the catalog, templates, and service health to developers.
That gives you a clean ownership boundary:
- Terraform owns cloud setup and external dependencies.
- Argo CD owns desired state in the cluster.
- Backstage owns discoverability and self-service UX.
Developer -> Backstage -> Template -> Git repo -> Argo CD -> EKSThe important point is that none of these tools replaces the others. They each solve a different layer of the contract.
Why We Should Build It This Way
An IDP fails when it is too generic. If the platform tries to support every possible workflow, it becomes a portal with no opinion. If it is too rigid, teams route around it.
The right balance is to standardize the parts that are expensive to rediscover and leave the rest flexible.
- Standardize how services are created.
- Standardize how ownership is captured.
- Standardize how workloads reach the cluster.
- Keep service implementation details in team-owned repos.
That structure gives developers speed without making the platform team the bottleneck for every change.
What To Validate Before You Scale
Before you call the platform done, validate these things:
- Can a developer find the service and its owner in the catalog?
- Can a developer create a new service from a template without filing a ticket?
- Can the platform team update one baseline and have it propagate through GitOps?
- Can you explain which team owns runtime failures versus template failures?
- Can you inspect service health from the portal without granting cluster-admin access?
If the answer to those questions is no, you have infrastructure and maybe a UI, but not a real IDP.
The strongest sign that the platform is working is that teams stop asking for bespoke setup and start asking for a better template or a better default. At that point the platform is no longer a project; it is a repeatable operating model.
Frequently Asked Questions
Q: Is Backstage the platform? A: No. Backstage is the portal and contract surface. The actual platform includes the runtime, automation, policy, and integration layers underneath it.
Q: Should every service be created through a template? A: Usually yes for the happy path, because templates create a repeatable baseline. The platform should still allow exceptions when a service legitimately needs a different shape.
Q: Do I need GitOps for an IDP? A: You do not strictly need it, but you usually want it. GitOps makes the platform auditable, reduces drift, and gives the platform team a consistent way to manage day-2 change.
Q: What is the biggest mistake teams make with IDPs? A: They build a portal before they define the contract. If the platform does not say what can be requested, created, and operated, the UI becomes a thin wrapper over manual work.



Comments
Post a Comment