Terraform Drift Detection and Remediation: A Safer Operating Model for Real Infrastructure
Terraform Drift Detection and Remediation: A Safer Operating Model for Real Infrastructure
Terraform drift is rarely just a tooling nuisance. This guide shows how to detect real drift, decide whether to revert or reconcile it, and build a safer remediation workflow around plan, -refresh-only, import, and selective lifecycle rules.
TL;DR
- Terraform usually exposes drift during normal planning because it refreshes managed objects before proposing changes.
terraform plan -refresh-onlyis for reviewing state-only reconciliation, not for blindly fixing accidental drift.- If the remote change is now the intended standard, update configuration first and then run a normal plan.
- Use
importwhen Terraform should adopt an existing object, and useignore_changesonly for narrow, deliberate shared ownership. - Build a classification workflow around drift events so emergency fixes do not silently turn into permanent configuration debt.
Drift Usually Starts as a "Small" Emergency Fix and Ends as a 3 A.M. Surprise
Most Terraform drift is not created by bad intentions. It usually starts with a fast console edit during an incident, a temporary security-group rule, a manually replaced instance, or a tag update made by another system. The problem is not the emergency change itself. The problem is what happens next, when nobody decides whether Terraform should revert it, absorb it, or share ownership of that setting with another process.
That is why drift remediation is not just a detection problem. Terraform already refreshes managed objects during planning, so you usually learn about drift the next time you run terraform plan. The hard part is choosing the right response without creating worse damage in state or production.
- Detect drift before a normal change window turns it into an accidental rollback.
- Separate accidental drift from intentional emergency changes.
- Update configuration before state when the desired end state has changed.
- Use state-only reconciliation sparingly and deliberately.
What Terraform Can Actually Detect, and What It Will Not Decide for You
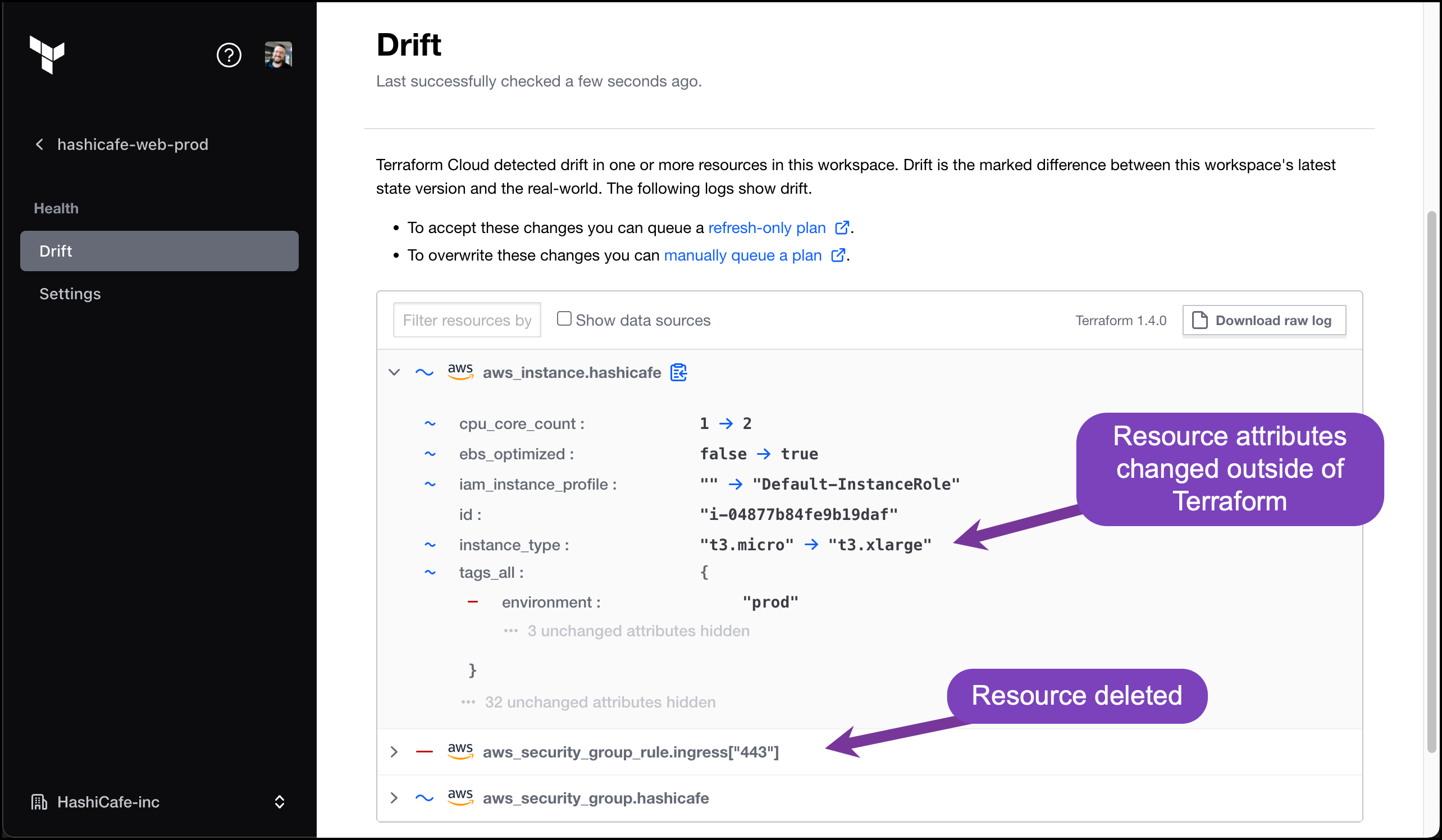
Terraform tracks resources through state. When a managed object changes outside the Terraform workflow, the next refresh during plan or apply can expose the difference between configuration, state, and the real remote object.
Two details from the HashiCorp docs matter here. A normal terraform plan refreshes current remote objects before proposing how to change infrastructure. A terraform plan -refresh-only switches the goal so Terraform proposes updates to state and outputs that match current remote reality.
That second mode is powerful, but it is easy to misuse. A refresh-only plan is not "fix drift" mode. It is "sync Terraform's records with what already happened" mode. If the remote change was accidental, syncing state just teaches Terraform to accept the mistake.
terraform init
terraform plan
terraform plan -refresh-only
HashiCorp also explicitly recommends the -refresh-only planning and apply flow instead of the older terraform refresh subcommand, because the old command overwrites state without the same review step. In production, that review matters because bad credentials, the wrong region, or a mistaken workspace can make Terraform believe resources disappeared when they did not.
A Practical Remediation Decision Tree
The cleanest drift workflow is not "run whatever command removes the diff." It is deciding which case you are actually in.
1. The remote change was wrong, so Terraform should revert it
If the desired state in code is still correct, review a normal plan and let Terraform converge the remote object back to configuration.
terraform plan -out=tfplan
terraform apply tfplan
2. The remote change was right, but configuration is now outdated
If the emergency fix should become the new standard, update Terraform code first. After that, run a normal plan again so Terraform sees aligned configuration and remote infrastructure. Do not jump straight to apply -refresh-only unless the configuration update genuinely cannot happen yet.
3. Terraform should start managing an existing remote object
Sometimes the problem is not drift inside a managed resource. It is that a real object now exists, but Terraform does not have it bound to configuration. That is an import problem, not a refresh-only problem.
terraform import aws_security_group.app sg-0123456789abcdef0
terraform plan
4. Another system is legitimately responsible for a narrow attribute
Some environments intentionally share management responsibility. A policy engine may stamp tags, or a controller may update an attribute after creation. That is where ignore_changes can be appropriate, but only when the ownership split is deliberate and documented.
resource "aws_instance" "app" {
ami = var.ami_id
instance_type = "t3.medium"
tags = {
Name = "app"
}
lifecycle {
ignore_changes = [
tags
]
}
}
Use this narrowly. If you apply it to avoid dealing with recurring drift, you are not fixing the operating model. You are hiding it.
A Better Drift Workflow for Teams: Review, Classify, Then Act
The biggest improvement most teams can make is classification before remediation.
- Run
terraform planon unchanged configuration. - Identify whether the diff came from an accidental edit, an intentional incident fix, a provider behavior change, or an object Terraform never properly adopted.
- Choose one response: revert through normal apply, update code, import the resource, or selectively share ownership.
- Only after that, decide whether
terraform apply -refresh-onlyis appropriate.
If you need state-only reconciliation because the emergency fix is accepted and infrastructure must not be touched, the safer sequence is still review first, then apply:
terraform plan -refresh-only
terraform apply -refresh-only
You can also use replacement intentionally when an object is degraded and in-place correction is not the best answer.
terraform plan -replace=aws_instance.app
That is not a generic drift command. It is a conscious declaration that the object should be recreated even if Terraform might otherwise attempt an update or no-op.
Why We Built It This Way
The right drift strategy is mostly about preserving trust in Terraform as a system of record. If engineers learn that emergency changes live forever in the console, Terraform becomes advisory. If they learn that Terraform will blindly erase every emergency fix on the next apply, they stop trusting the automation during incidents.
The stronger middle path is to treat every drift event as a classification problem and then codify the decision. That is also why scheduled planning matters. A normal change review will surface drift eventually, but by then the blast radius is larger because the drift is mixed with unrelated work. Running recurring plans against unchanged configuration gives you cleaner signals and smaller remediation decisions.
The goal is not zero drift in all cases. The goal is zero ambiguous drift.
Import Blocks, Shared Ownership, and When Not to “Fix” Drift
One of the more technical failure modes in real Terraform estates is confusing unmanaged infrastructure with drift inside managed infrastructure. If a remote object already exists but Terraform has never been the source of truth for it, that is usually an adoption problem, not a remediation problem.
That is where import blocks are cleaner than an ad hoc CLI-only workflow, especially in review-heavy environments:
import {
to = aws_security_group.app
id = "sg-0123456789abcdef0"
}
With an import block in configuration, the adoption step is visible in version control and can be reviewed in the same pull request as the resource definition. That is a stronger operating model than importing manually on a laptop and hoping everybody else understands what happened.
The same logic applies to shared ownership. If another system is supposed to mutate a narrow attribute after creation, document that boundary explicitly and scope ignore_changes to the minimum field set. If you reach for ignore_changes because your Terraform plans are noisy and you do not know why, stop and fix the ownership model first.
- Confirm whether the object was already Terraform-managed.
- Decide whether the remote change is accidental, intentional, or evidence of split ownership.
- Prefer configuration updates and import blocks over state-only shortcuts.
- Use
-refresh-onlyonly when the infrastructure is correct and Terraform’s record is what needs to catch up.
Frequently Asked Questions
Q: Is terraform refresh still the right command for drift?
A: HashiCorp still documents it, but recommends the reviewable -refresh-only flow instead. The older subcommand updates state directly and is easier to misuse when credentials or context are wrong.
Q: Does a normal terraform plan already detect drift?
A: Yes, because Terraform refreshes managed objects before planning by default. The important nuance is that normal planning proposes how to change infrastructure to match configuration, while refresh-only planning proposes how to change state to match infrastructure.
Q: Should I always reconcile intentional hotfixes with apply -refresh-only?
A: No. If the hotfix should become permanent policy, update configuration first whenever possible. Refresh-only is most useful when infrastructure must remain as changed and you need Terraform’s records to catch up safely.
Q: What is the most dangerous drift anti-pattern?
A: Treating ignore_changes as a general cure. It is a narrow tool for deliberate shared ownership, not a way to avoid fixing broken workflows or undocumented console changes.



Comments
Post a Comment